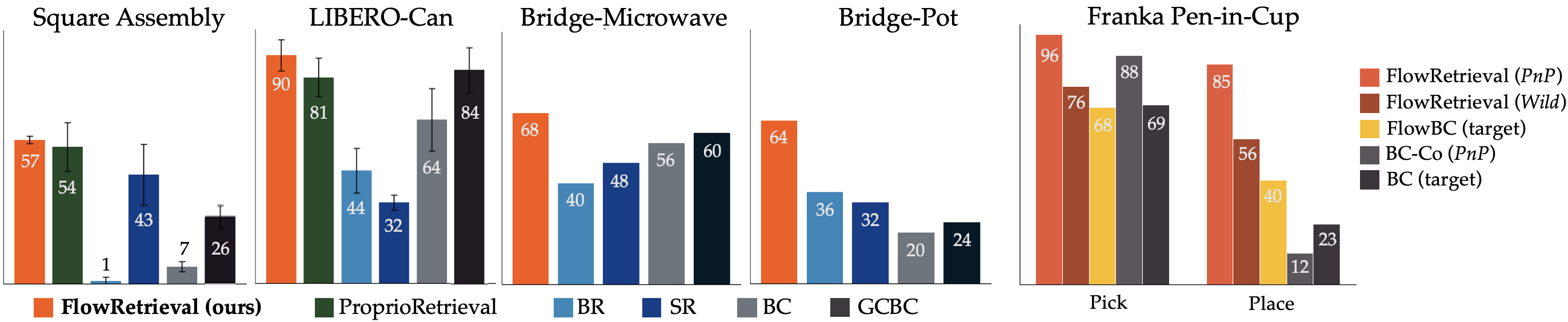
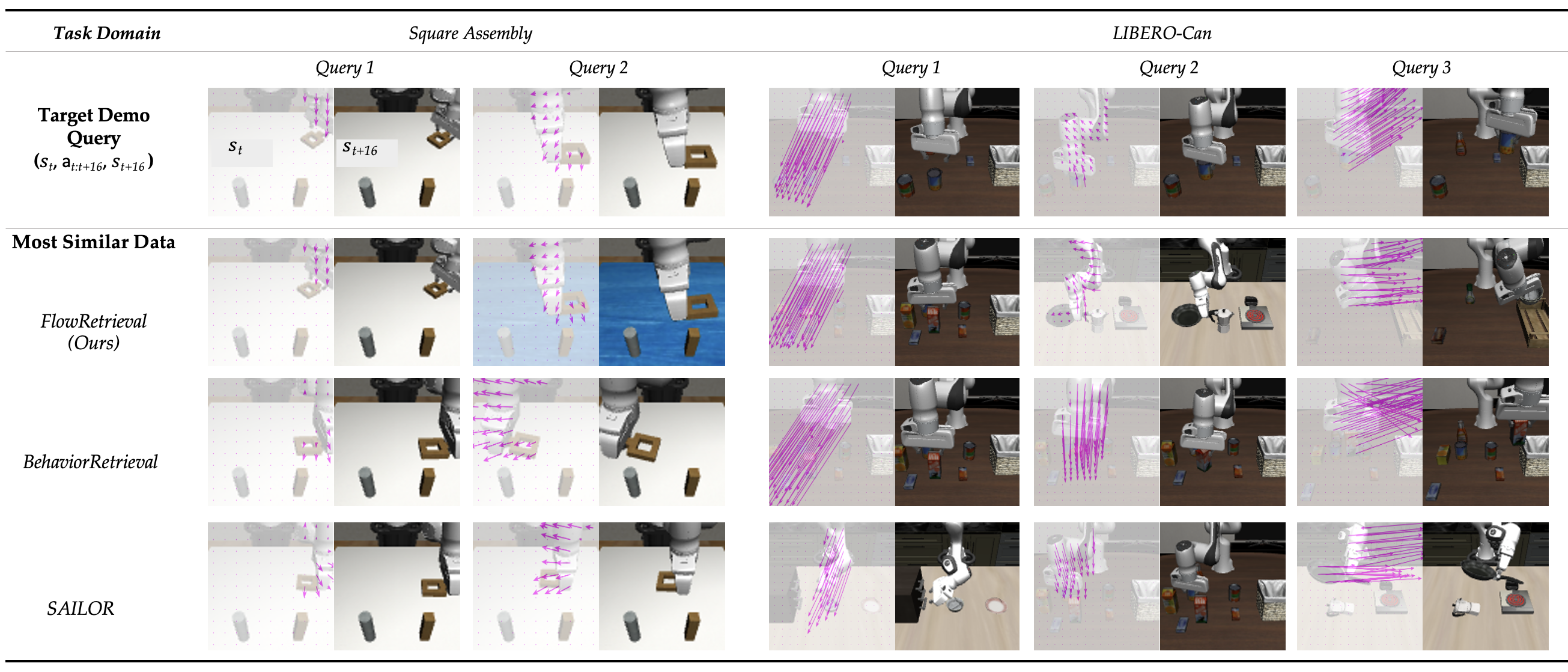
Method Overview
We learn a motion-centric latent space for retrieving motions similar to target data from prior data and further guide policy learning with optical flow.
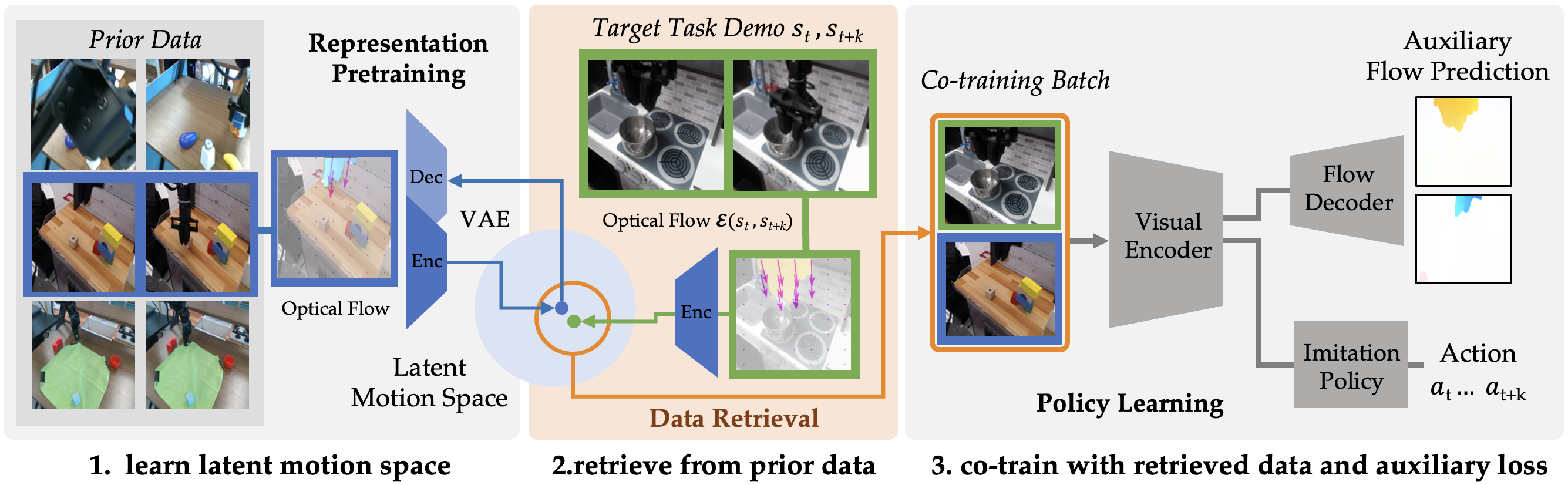
- Motion-Centric Pretraining: FlowRetrieval acquires a motion-centric latent space by computing optical flow between the current frame and a future frame of the robot's RGB visual observations, and employing a variational autoencoder (VAE) to embed the optical flow data.
- Data Retrieval with the Learned Motion-Centric Latent Space: We select the nearest neighbors of target task in the latent space from previously collected data.
- Flow-Guided Learning: During policy learning, FlowRetrieval leverages an auxiliary loss of predicting the optical flow as additional guidance for representation learning, encouraging the model to encode the image with enough details to reconstruct optical flow alongside predicting the action.